
Activer le mode zen
Ressource au format PDF
Classification
L'intelligence artificielle, c'est quoi ? - Une explication pour les physiciens
L'intelligence artificielle : introduction et applications en physique (1/3)
21/06/2021
Résumé
Vous êtes-vous déjà demandé s'il était possible de créer sa propre IA ? Et de l'utiliser dans ses recherches en physique ou dans l'industrie ? C'est ce que nous allons voir dans cette série de 3 articles : L'intelligence artificielle : introduction et applications en physique.
Dans ce premier article nous présentons l'intelligence artificielle, où peut-on la rencontrer, à quoi sert-elle et nous présentons son potentiel.
Colin Bernet est chargé de recherche au CNRS, créateur du blog https://thedatafrog.com, et cofondateur de https://cynapps.ai.
Table des matières
Introduction
Tous les jours ou presque, chacun d'entre nous utilise une intelligence artificielle (IA), parfois sans même le savoir !
Prenons l'exemple de ma journée d'hier :
Je devais donner une conférence sur l'IA pour une association d’entreprises à Vienne, en région Lyonnaise. Le matin, je termine mes diapos avec quelques recherches google pour trouver des images, et quelques requêtes de traduction anglais-français.
C'était ma première conférence "en présentiel" depuis des mois ! Pour être sûr d'arriver à l'heure, je lance mon appli de navigation, qui estime le temps de trajet en temps réel et me propose une modification d'itinéraire pour éviter les fameux bouchons lyonnais. Le devoir accompli, une fois rentré chez moi, je me pose devant Netflix qui me propose un film.
Dans cette simple journée, j'ai utilisé cinq applications de l'IA :
- l'étiquetage de photos, qui repose sur la détection d'objets dans des images. La recherche de photos se fait ensuite sur le résultat de cette détection. Pour essayer, tapez “pizza” dans Google images !
- la traduction automatique ;
- la prédiction d'une grandeur, ici un temps de trajet ;
- la reconnaissance et la synthèse vocale de l'application de navigation ;
- le système de recommandation de Netflix.
Ces applications grand public sont toutes développées par des GAFA ou d'autres grandes entreprises américaines.
Vous êtes-vous déjà demandé s'il était possible de créer sa propre IA ? Et de l'utiliser dans ses recherches en physique ou dans une entreprise traditionnelle ?
C'est ce que nous allons voir dans cette série de 3 articles, dont voici le plan :
- Intelligence artificielle et modélisation statistique
- La révolution en cours
- Votre première IA avec le langage python
- Quelques applications en physique
- Application industrielles
1. Intelligence artificielle et modélisation statistique
Si vous lisez ceci, je suis presque sûr que de l'IA, vous en faites déjà !
En effet, l'un des outils les plus utilisés en sciences expérimentales est la modélisation statistique.
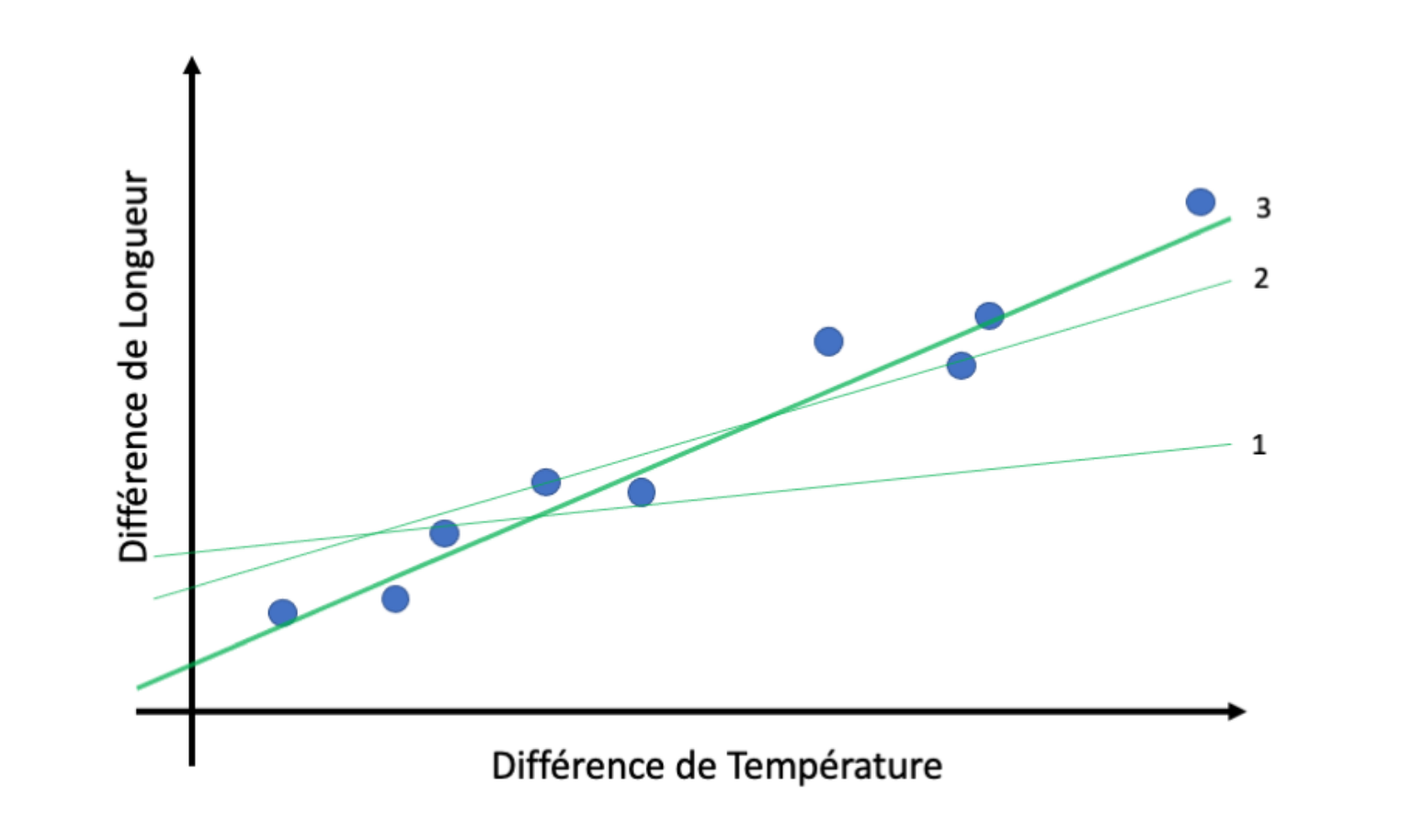
Prenons le cas de la dilatation thermique d'une barre d'acier. Par rapport à une longueur et une température de référence, on peut mesurer au cours du temps la différence de longueur de cette barre ainsi que la différence de température, figure 1.
Ici, la modélisation statistique consiste d’abord à tracer la différence de longueur en fonction de la différence de température, puis à ajuster une courbe aux données :
 Source - © 2021 C. Bernet |
Dans ce cas, les données semblent linéairement corrélées. On décide donc d'ajuster une simple droite, définie par deux paramètres a et b : la pente et l'ordonnée à l'origine.
En d'autres termes, nous avons modélisé les données pour leur donner du sens, et notre modèle comporte seulement deux paramètres.
Le modèle nous permet aussi de faire des prédictions : si on choisit une différence de température quelle qu'elle soit, on peut en déduire facilement la différence de longueur correspondante grâce à la droite 3, figure 1.
Généralement, l'ajustement d'un modèle est un processus itératif : on commence par choisir des valeurs aléatoires pour les paramètres, puis un algorithme d'optimisation modifie ces valeurs à chaque étape (1, 2, puis 3, figure 1) pour que le modèle se rapproche des données.
L'apprentissage machine (machine learning), c'est tout simplement ça : l'ajustement d'un modèle à des données !
Et quand on parle d'entraînement d'une IA, on se réfère à l'adaptation itérative des paramètres du modèle.
Alors pourquoi en fait-on tout un plat ?
2. La révolution de l’intelligence artificielle
C'est juste une question d'échelle.
D’abord, les modèles les plus avancés à l’heure actuelle, notamment dans le domaine du traitement du langage, peuvent comporter plus de 100 milliards de paramètres GPT-3 [1], alors que notre modèle de dilatation thermique n’en a que deux.
Ensuite, ces modèles nécessitent une quantité phénoménale de données, souvent collectées automatiquement à partir de millions, voire de milliards de pages web. Dans l’exemple ci-dessus, nous avons entraîné notre modèle avec seulement 9 points de données.
Enfin, ces modèles sont capables de travailler sur des données de très haute dimension.
Dans l'exemple de la dilatation thermique, nous avons considéré des données à deux dimensions : chaque point est représenté par deux variables, la différence de longueur et la différence de température.
Un réseau de neurones pour la classification d’image travaille quant à lui sur des images faites de pixels avec, pour chaque pixel, trois niveaux de couleur (rouge, vert, bleu). Ainsi, une image 200x200 pixels peut être considérée comme un "point" dans un espace à 200x200x3 = 120 000 dimensions !
Tout cela a été rendu possible grâce à deux avancées technologiques :
- les GPU (processeurs de cartes graphiques), dont le développement a d'abord été poussé par l'industrie du divertissement. De nos jours, ils sont aussi utilisés pour les calculs parallèles comme les entraînements de modèles IA, et surtout pour le minage de crypto-monnaies (la création de bitcoins par exemple).
- Internet, qui est un collecteur de données à l'échelle planétaire pour l'entraînement des IA.
3. Deep learning pour la classification d’images
L'essor de l'intelligence artificielle repose actuellement sur l'apprentissage profond (deep learning), dans lequel on utilise des réseaux de neurones constitués de nombreuses couches empilées sur une grande profondeur, et comprenant énormément de paramètres, figure 2 :
![Réseau convolutionnel VGG16 [2], pour la classification d'images](https://culturesciencesphysique.ens-lyon.fr/images/articles/ia-bernet/VGG16.png) Source - © 2021 M. Ferguson |
Le réseau VGG16 [2] ci-dessus est d’abord constitué de cinq blocs (conv1 à conv5), contenant chacun deux ou trois couches convolutionnelles. La première de ces couches scanne l’image en entrée et produit une nouvelle image avec dans chaque pixel 64 valeurs, analogues à des couleurs. Chaque pixel contient donc plus d’information qu’auparavant, et cette information supplémentaire provient des pixels voisins dans l’image d’entrée. Les couches suivantes fonctionnent de la même manière, à partir de l’image de la couche précédente.
Le réseau comporte aussi des couches de “max pooling”, qui réduisent d’un facteur deux le nombre de pixels en hauteur et en largeur. Ces couches ont pour but de simplifier le réseau et de lui permettre de détecter des objets occupant une place importante dans l’image originelle.
Ainsi, à la sortie de la partie convolutionnelle (avant les couches fc discutées ci-dessous), on obtient une image de 7x7 pixels contenant chacun 512 valeurs. À ce stade, l’image a donc été convertie en un jeu de 25088 valeurs, qui encodent ce que le réseau de neurones a compris de l’image.
Ce jeu de valeurs passe ensuite dans un réseau de neurones simple tel que celui que vous utiliserez dans l'article suivant : « Entraînez votre première IA en python » pour les chiffres manuscrits, avec deux couches de 4096 neurones chacunes (fc6 et fc7), puis une couche de 1000 neurones (fc8).
Pourquoi 1000 ? car VGG est entraîné à classer les images de l’échantillon ImageNet [3] dans 1000 catégories. En d’autres termes, le réseau prédit pour chacune des 1000 catégories la probabilité que l’image appartienne à cette catégorie. Ainsi, la sortie des 1000 neurones de la dernière couche est une probabilité entre 0 et 1, et la somme de ces probabilités vaut 1.
Voici un exemple, figure 3, des résultats obtenus avec le réseau AlexNet [4], un précurseur de VGG16 :
![Classification d'images de ImageNet par le modèle AlexNet [4].](https://culturesciencesphysique.ens-lyon.fr/images/articles/ia-bernet/imagenet.png) Source - © 2021 C. Bernet Figure 3. Classification d'images de ImageNet par le modèle AlexNet [4]. Sous chaque image, les catégories les plus probables sont indiquées avec leurs probabilités respectives. Par exemple, le léopard est correctement classifié comme léopard, puis avec une probabilité moindre comme jaguar. |
Comme vous pouvez le voir, les performances sont impressionnantes, même pour AlexNet, un réseau qui a plus de dix ans.
Mais quelle est l’utilité de pouvoir reconnaître correctement une image de dalmatien ou de mite ?
En fait, lors de l’entraînement sur ImageNet, le réseau de neurones apprend à voir. Les premières couches convolutionnelles sont capables de détecter des lignes d’orientation différente, très localisées dans l’image. Les couches suivantes identifient des textures telles que le pelage du léopard. Et les couches convolutionnelles finales reconnaissent des objets complexes, comme le léopard lui-même, ou un champignon.
On peut donc l'adapter à une autre tâche de vision comme différencier des espèces de fleurs. Pour cela, on remplace simplement les couches fc6, fc7 et fc8 par un nouveau sous-réseau dédié à cette nouvelle tâche. Alors, on aurait n neurones sur la dernière couche, ou n correspond au nombre d’espèces de fleurs à considérer. Après cela, il suffit d’entraîner uniquement ce nouveau sous-réseau sur l’échantillon d’images de fleurs, étiqueté par un humain, tout en gardant fixés les paramètres de la partie convolutionnelle.
Cette technique, appelée réglage fin ou transfert d’apprentissage (transfer learning), est essentielle dans le déploiement de réseaux de neurones sur des cas concrets, car elle permet d’entraîner un modèle avec un nombre limité d’images étiquetées, de l’ordre de 1000 à 10 000.
Série de 3 articles : L'intelligence artificielle : introduction et applications en physique
Références
[1] GPT-3 https://en.wikipedia.org/wiki/GPT-3
[2] VGG https://arxiv.org/abs/1409.1556
[3] ImageNet https://www.image-net.org/
[4] AlexNet https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
Pour citer cet article :
L'intelligence artificielle, c'est quoi ? - Une explication pour les physiciens, Colin Bernet, juin 2021. CultureSciences Physique - ISSN 2554-876X, https://culturesciencesphysique.ens-lyon.fr/ressource/IA-Bernet-1.xml