
Activer le mode zen
Ressource au format PDF
Classification
Machine learning appliqué au domaine de l’énergie
30/05/2022
Résumé
Dans cet article nous présentons l'utilisation de l'intelligence artificielle dans le domaine de la prédiction de la consommation en électricité d'un bâtiment.
Table des matières
Introduction
Vous êtes désormais familier avec le concept d’apprentissage machine (machine learning) [« L'intelligence artificielle, c'est quoi ? - Une explication pour les physiciens »], et vous avez entrevu des applications pour cette technologie dans le milieu de la physique et de l’industrie [« L'intelligence artificielle : introduction et applications en physique »]. Vous avez sûrement aussi entendu parler du 6ème rapport du Groupe d'experts intergouvernemental sur l'évolution du climat (GIEC), sorti en août 2021, et qui correspond à la dernière mise à jour de l’état des connaissances scientifiques et de la compréhension physique sur le climat (une analyse synthétique est disponible [« Synthèse et analyse du nouveau rapport du GIEC »]).
Ce rapport indique que “le changement climatique s’accélère et s’intensifie”. Le changement climatique est plus que jamais en action et une des priorités est de diminuer les émissions de gaz à effet de serre. En accord avec cette urgence, l’Agence internationale de l’énergie (IEA) préconisait trois mois auparavant de “déployer massivement toutes les technologies d'énergie propre disponibles, telles que les énergies renouvelables”. Plus globalement, il faut que l’on apprenne à maîtriser notre consommation d’énergie afin de l’optimiser et de la réduire.
L’intelligence artificielle (IA), notamment par sa capacité à prédire, a un rôle à jouer dans la solution à ces défis. Mais ces défis sont complexes car étroitement liés au temps, variable qu’il faut apprendre à maîtriser avec l’IA. Les outils de l'IA sont amenés à prendre une part grandissante dans les activités de l’énergie à mesure que les systèmes se décentralisent et se complexifient. Même si les applications de l'IA sont pour l’instant marginales sur les réseaux, elles peuvent à moyen terme devenir des outils de la transition énergétique pour les territoires [1]. C’est ce que nous allons voir à travers cet article.
1. Atouts de l’IA pour les défis énergétiques
1.1 Prédire pour anticiper et s’adapter
Le premier atout de l’apprentissage automatique (machine learning) est qu’il permet, à partir d’un comportement passé, de prédire ce comportement dans le futur. Par exemple, au niveau national, la consommation d’énergie de la France est impactée par les évènements qui rythment le pays. On peut ainsi utiliser l’IA, en association avec les données issues d’un réseau social comme Twitter, pour essayer de repérer en avance de potentielles situations qui impliquent des pics de consommation d’énergie. Par exemple, un nombre élevé de réactions à propos d’un match de foot important est souvent corrélé à un important pic de consommation énergétique à la mi-temps du match. Néanmoins, le nombre de données à traiter est massif et la gestion de l'entraînement de cet IA est complexe d’un point de vue théorique mais aussi pratique, à travers les serveurs et stockages nécessaires à l’alimentation de l’IA en données temps-réel.
On a également vu que le développement des énergies renouvelables fait partie des solutions face au changement climatique. Seulement, si l'on s’intéresse au photovoltaïque, qui correspond à l’énergie renouvelable avec le plus de potentiel, cette énergie présente un problème d’adéquation entre la phase de production et les besoins en consommation électrique. En effet, une installation solaire va produire de l’électricité selon une cloche située du lever au coucher du soleil. Or, si l'on compare à une consommation d’électricité résidentielle, cette dernière va plutôt apparaître à travers deux pics de consommation, un premier le matin et surtout un deuxième plus important le soir vers 19h-20h, figure 1.
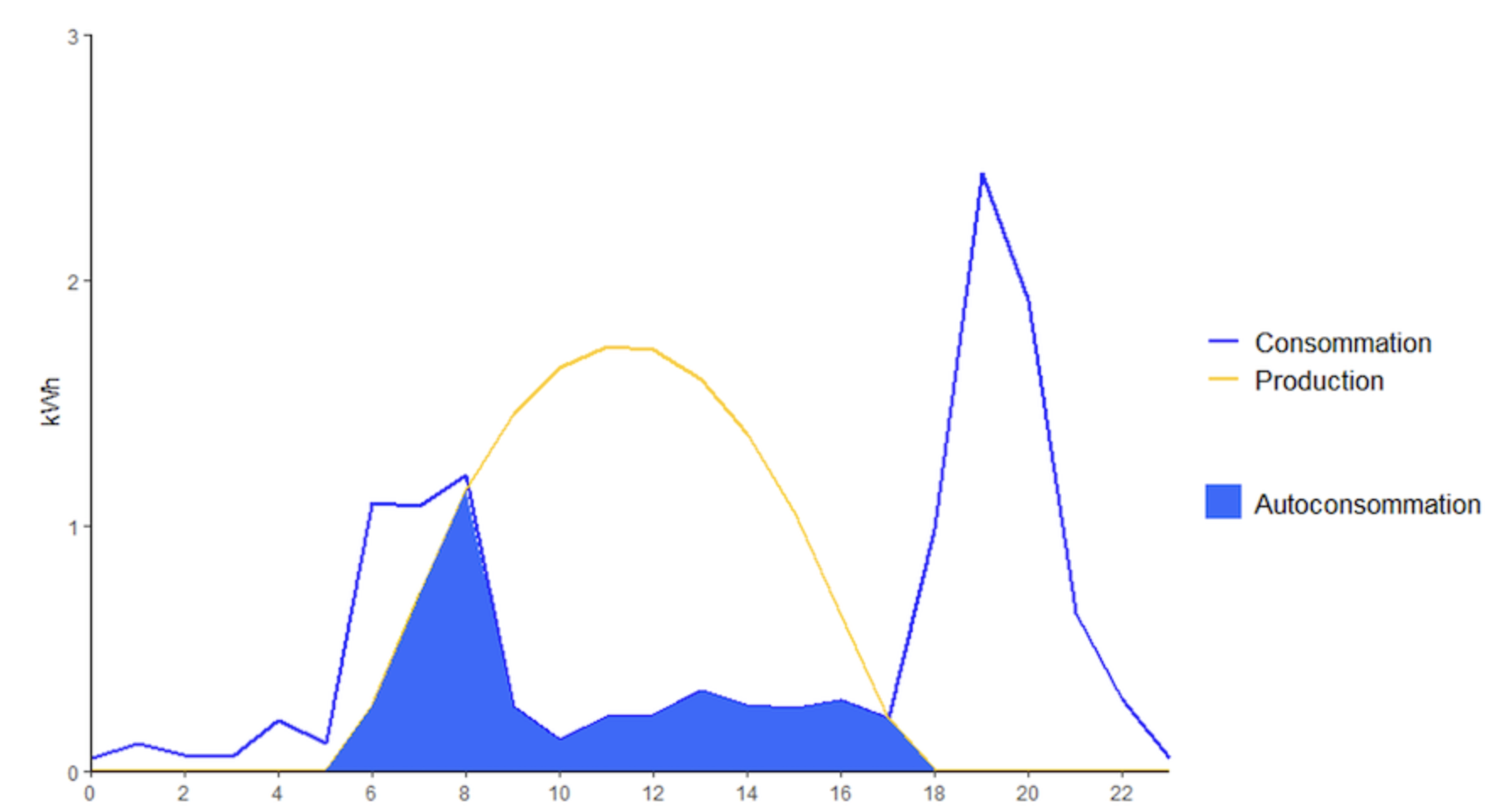 |
Prédire la consommation grâce à l’IA, c’est aussi anticiper cette inadéquation entre production et consommation. Et en parallèle de cette anticipation, il se développe de plus en plus d’outils pour corriger ce phénomène. Grâce à une IA entraînée sur des données de consommations passées, il est possible d’obtenir une prédiction de consommation électrique par exemple la veille [3] et ainsi de mettre en place des stratégies comme de la flexibilité (directe à travers de la domotique ou indirecte à travers des signaux pour les habitants) [4] ou du stockage pour optimiser la simultanéité des consommations électriques résidentielles et des productions électriques issues du photovoltaïque.
Cependant, l'entraînement de l’IA nécessite un accès aux données de consommation des foyers. C’est désormais possible grâce aux compteurs communicants type Linky [5] mais pour que l’IA soit efficace, cela nécessite un certain historique pour pouvoir l'entraîner.
1.2 Prédire pour repérer les anomalies et les corriger
On a vu précédemment que l’IA pouvait servir à prédire un comportement de consommation énergétique afin de s’adapter et pouvoir mieux y répondre. Mais l’IA, grâce à sa capacité de prédiction, permet aussi de construire un comportement de référence, comme par exemple le comportement normal de consommation d’un bâtiment. Effectivement, de plus en plus de bâtiments sont monitorés à l’aide de batteries de capteurs afin d’optimiser leur consommation énergétique. Avec un historique suffisant et propre de données de consommation énergétique, il est ainsi possible de lui prédire un comportement de consommation.
L’intérêt d’avoir ce comportement de référence est d’observer les données réelles pour analyser les causes lorsque le comportement réel de consommation s’éloigne du comportement de référence. Deux causes majeures de valeurs aberrantes par rapport à une prédiction de consommation d’un bâtiment peuvent être : un dysfonctionnement de capteur et/ou une mauvaise gestion énergétique du bâtiment [6]. Dans les deux cas, la détection de ces anomalies permet de résoudre le problème et ainsi d’optimiser la gestion énergétique du bâtiment.
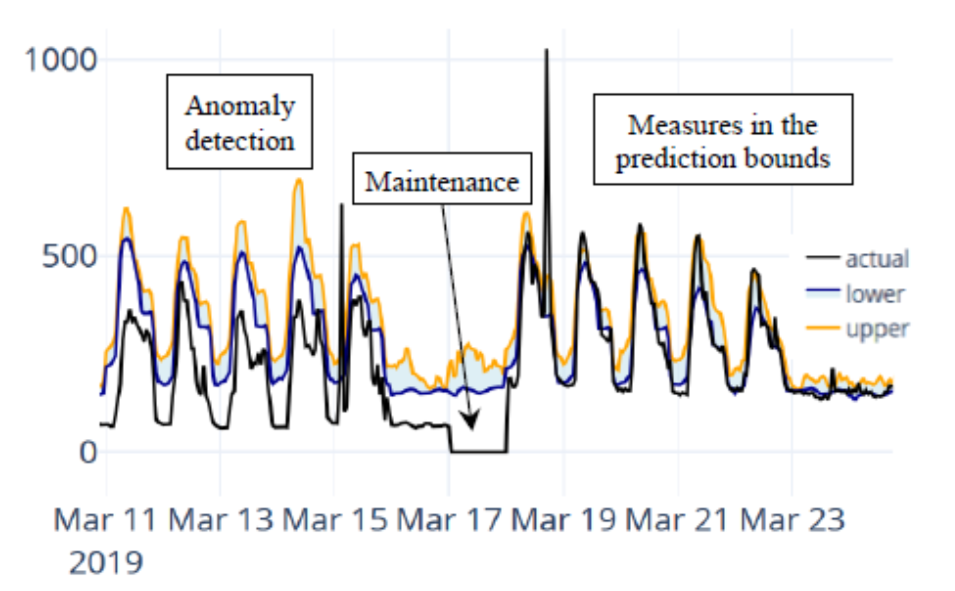
Sur la figure 2, on a, par exemple, le comportement de consommation énergétique d’un bâtiment qui a été prédit par un modèle d’apprentissage automatique appelé Gradient Boosting. Ce modèle de machine learning est une version améliorée du modèle simple d’arbres de décision [7].
En entraînant le modèle sur des données de qualité différentes, il a été possible de construire un intervalle de confiance (entre les courbes jaunes et bleues) dans lequel le comportement est considéré comme normal. Ainsi, si le comportement réel sort de cet intervalle, il est considéré comme anormal. Cette surveillance a permis de détecter un besoin de maintenance et ainsi de corriger le comportement anormal de ce bâtiment. Cette détection a été possible car le bâtiment en question est équipé de capteurs de consommation depuis 2016 [3].
Pour plus de précisions sur la modélisation et la gestion énergétique des bâtiments à l’aide de l’IA, on pourra consulter le concept de Smart Building [8].
Plus globalement, on peut étendre ce principe pour d’autres applications de maintenance. Par exemple, la surveillance à distance du comportement de production d’un parc photovoltaïque en comparaison avec son comportement de référence prédit par IA permet de n’intervenir sur place qu’en cas de besoin. La maintenance prévisionnelle est considérée comme l’optimum en termes de coûts de maintenance et d’efficacité.
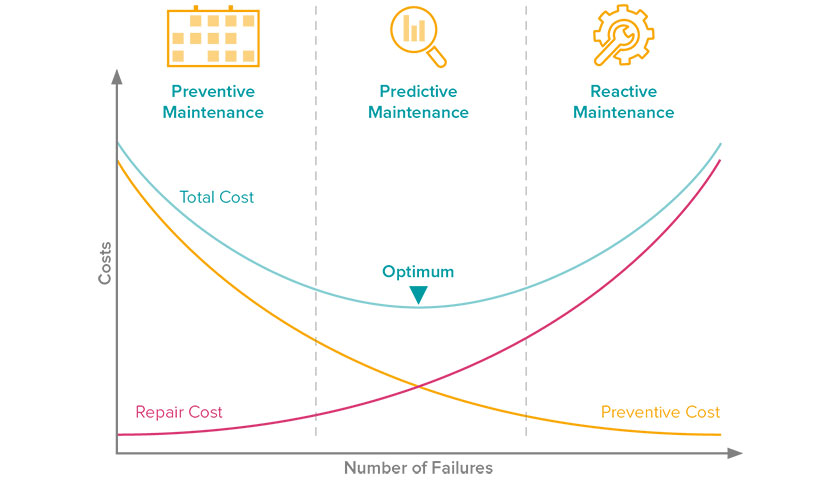 Figure 3. Courbes Coût - Pannes en fonction des types de maintenance Source : Maintenance prévisionnelle [9]. |
2. Focus sur les séries temporelles
Pour pouvoir effectuer les prédictions à l’aide de modèle de machine learning et obtenir les bénéfices évoqués précédemment, il va falloir composer avec des données qui sont souvent reliées au temps, c’est ce qu’on appelle les séries temporelles. Elles sont particulièrement présentes dans le milieu de l’énergie, où les données utilisées correspondent souvent à des données météo, à des relevés de consommation ou des relevés de production énergétique.
2.1 Prédiction des séries temporelles
Dans le domaine de l'énergie, les séries temporelles sont le type de données le plus courant. Il s’agit simplement d’une série indexée par le temps. Comme par exemple, la consommation électrique du bâtiment GreEn-ER, qui abrite l’école d’ingénieur Grenoble INP Ense3 et le laboratoire G2ELab, en fonction de l’heure de la journée.

L’utilisation de l’IA sur ce genre de données est très utile car concrètement, cela peut permettre de prédire la consommation future. En effet, l’idée principale est de se servir des données passées pour en prédire de nouvelles. Pour ce faire nous pouvons par exemple utiliser les réseaux de neurones récurrents avec les forêts d’arbres décisionnels aléatoires (Random Forest Regression) ou avec une architecture LSTM (Long Short-Term Memory).
Forêts d’arbres décisionnels aléatoires
Par définition, une forêt est un ensemble d’arbres, ici il s’agit d’arbres de décision de type arbre de régression. L’objectif est d’entraîner un certain nombre d’arbres, disons \(N\) arbres, sur \(N\) portions aléatoires issues du jeu de données initial. Pour effectuer une prédiction, l’algorithme donne une nouvelle entrée aux \(N\) arbres, ce qui donne \(N\) valeurs possibles. Le résultat est alors simplement obtenu en calculant la moyenne des \(N\) résultats.
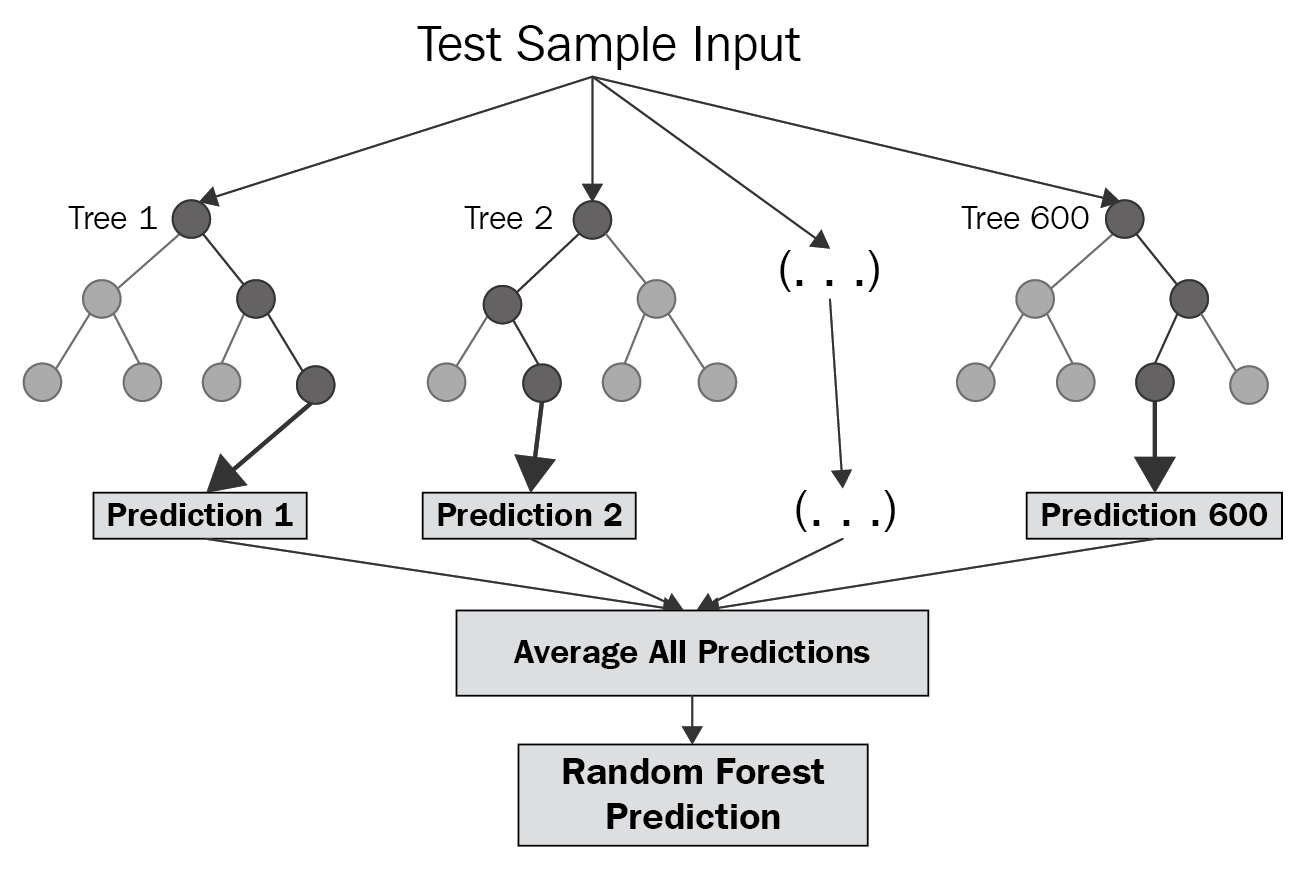 Figure 5. Schéma de principe des forêts d’arbres décisionnels aléatoires Source : Random Forest Regression [10]. |
Pour plus d’informations, on pourra retrouver le fonctionnement des forêts d’arbres décisionnels aléatoires et leur implémentation en Python à l'aide de la référence Understanding random forest [11].
Réseaux récurrents et cellules LSTM
Un réseau de neurones récurrents est un modèle très simple qui permet de garder en mémoire une valeur \(v\) qui va permettre de prédire la suivante. La valeur de \(v\) deviendra alors la dernière valeur prédite et ainsi de suite. Ce réseau se compose de couches de neurones artificiels.
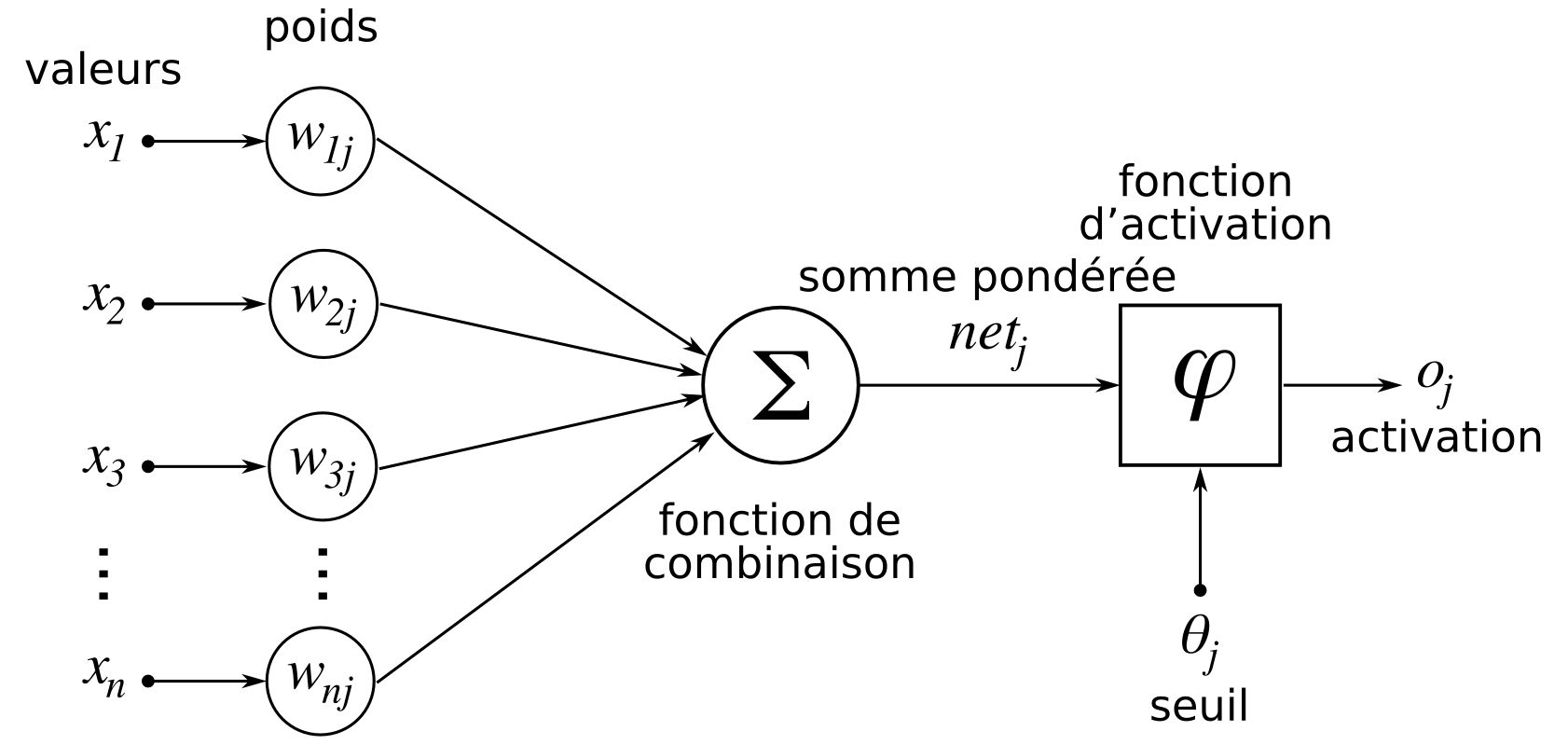 Figure 6. Schéma d’un neurone artificiel Source : Wikimedia. |
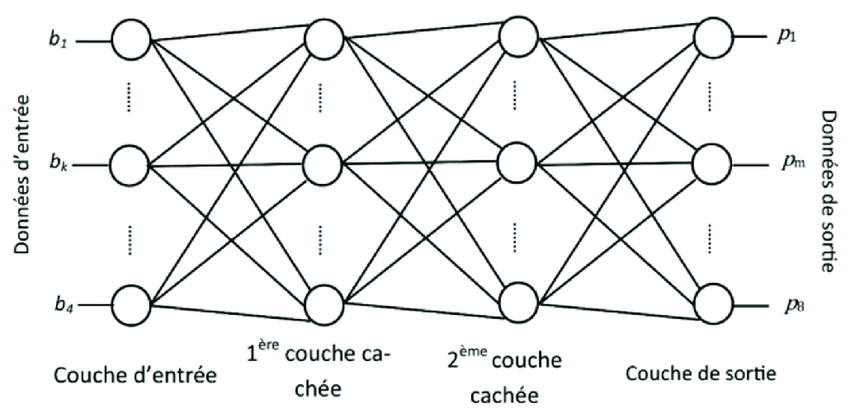 Figure 7. Schéma d’un réseau de neurones artificiels Source : Solofo Rakotondraompiana, ResearchGate. |
Le défaut principal de ces réseaux vient de ce qui est appelé le problème de la disparition du gradient. En effet, ces réseaux optimisent leur sortie grâce à une rétropropagation à travers leurs différentes couches, ce qui leur permet d’attribuer un poids plus ou moins important aux différentes couches. Plus ces couches cachées sont nombreuses et plus la mémoire théorique du réseau est grande. Mais le problème est que plus une couche est ancienne, plus elle devient insignifiante à cause du système de rétropropagation. Ainsi, même si une couche est considérée comme importante pour optimiser la sortie du réseau, son impact sur la sortie est amoindrie si le nombre de couches cachées augmentent.
C’est là qu’interviennent les cellules LSTM. Ces cellules disposent d’un système de portes d’oubli, qui va permettre de trier les informations et les sélectionner. Ainsi, les réseaux LSTM permettent de retarder grandement le problème de la disparition du gradient et de conserver la prise en compte d’anciennes couches [12].
Cependant, les réseaux LSTM ne sont pas magiques et à ajouter trop de cellules LSTM à la suite, on retombera sur le problème de la disparition du gradient, il faut donc se tourner vers d’autres méthodes pour des prédictions sur le long et très long terme. Néanmoins, les LSTM restent un outil très puissant sur les séries temporelles [13][14].
2.2 Exemples
Comme un exemple vaut mieux qu’un long discours, alors allons-y ! On va essayer de prédire la consommation globale du bâtiment GreEn-ER à l’aide des deux modèles présentés. La réalisation concrète en Python de cette prédiction est disponible au sein d’un Notebook : « Introduction à la prédiction de séries temporelles », [15].
Reprenons notre consommation globale du bâtiment GreEn-ER entre le 16/12/2021 et le 23/01/2022, figure 8.
Les données sont récupérées toutes les heures, on a donc 24 données par jour. On va prendre les 11 dernières heures pour prédire la 12ème. Pour mesurer la précision du résultat, on utilisera le coefficient de détermination \(r^2\). Plus ce coefficient est proche de 1, plus les prédictions sont proches des valeurs exactes et donc meilleur est le modèle.
Forêts d’arbres décisionnels aléatoires
On va prédire pour chaque pas de temps horaire la valeur de consommation énergétique. Pour cela, on entraîne une forêt aléatoire de 5 arbres (d’une profondeur maximale de 4) sur 11 heures afin de prédire la 12ème heure. Puis, on passe au pas de temps suivant et on effectue le même processus.
On peut enfin observer les résultats pour cette forêt aléatoire de 5 arbres, figure 9.
 Coefficient \(r^2\) = 0.89 |
Les résultats obtenus par ce modèle sont probants. Les prédictions sont proches des valeurs réelles, ce qui est également traduit par un coefficient \(r^2\) proche de 1.
Une autre variable à prendre en compte est le temps nécessaire pour faire fonctionner le modèle. Dans le cas présent, il aura fallu 0,24 secondes de temps de calcul au modèle de forêts d’arbres décisionnels aléatoires, ce qui est un temps plutôt rapide pour un modèle d’apprentissage automatique.
LSTM
On peut effectuer la même prédiction, mais en utilisant cette fois un réseau LSTM de 100 cellules, figure 10.
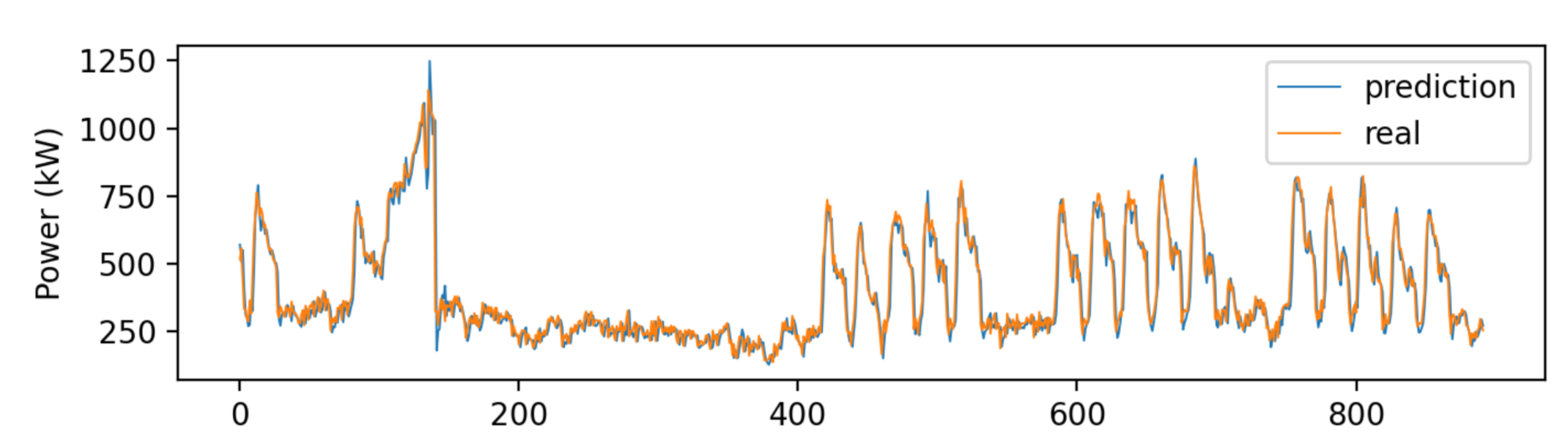 Coefficient \(r^2\) = 0.91 |
Les résultats sont meilleurs avec le réseau LSTM qu’avec les arbres décisionnels. On voit que le réseau LSTM arrive à mieux prédire les pics, là où les arbres décisionnels aléatoires forment des plateaux. En conséquence, le coefficient de détermination est plus proche de 1. Néanmoins, il aura fallu 48 secondes de temps de calcul au réseau LSTM pour atteindre ces résultats, ce qui est significativement plus important que dans le cas des arbres décisionnels aléatoires.
Conclusion
À travers cet article, vous avez vu que l’apprentissage machine (machine learning) avait de nombreuses applications dans le domaine de l’énergie. C’est principalement sa capacité de prédiction qui permet deux actions principales. D’une part, l’IA nous permet d’anticiper les consommations énergétiques à différentes échelles afin de mettre en place des stratégies d’adaptation (flexibilité, stockage).
D’autre part, l’IA nous fournit un comportement de référence qui sert à repérer et corriger les structures monitorées comme les bâtiments intelligents par exemple. Toutefois, l’ensemble de ces prédictions n’est possible que s’il existe une quantité suffisante et exploitable de données. Sans ces données, le modèle de machine learning manquera d'entraînement et les possibilités décrites précédemment perdront grandement en efficacité. Ces données sont très souvent temporelles lors d’une application au domaine de l’énergie et cette particularité est une complexité technique qu’il faut prendre en compte afin d’utiliser correctement les modèles de machine learning.
Ainsi, l’IA et, plus globalement, la Data Science, sont des outils particulièrement intéressants dans le domaine de l’énergie. Ils sont cependant encore trop sous-estimés et leur présence dans les cursus scolaires relatifs à l’énergie est encore restreinte [16].
Références
- [1] Thèse professionnelle de Nicolas Omnes, L’intelligence artificielle dans les micro grids énergétiques, simple utopie ou réalité de demain ?, Ecole des Ponts Mines ParisTech, 2019.
- [2] Modèle économique de l'autoconsommation photovoltaïque, Encyclopédie de l'énergie, consulté en mars 2022.
- [3] Machine learning on buildings data for future energy community services, Benoît Delinchant, Gustavo F. Martin Nascimento, Tiansi Laranjeira, Thi-Tuyet-Hong Vu, Muhammad S. Shadid, Frédéric Wurtz, SGE 2021, Symposium de Génie Electrique 2021, Nantes 6-8 juillet 2021.
- [4] L’intelligence artificielle, pilote de la flexibilité électrique, La gazette des Communes, 2019.
- [5] Décentralisation énergétique en France 2010-2020 : l’irruption du numérique et des énergies renouvelables, Encyclopédie de l'énergie, consulté en mars 2022.
- [6] Outlier Detection in Buildings’ Power Consumption Data Using Forecast Error , Energies 2021, 14, 8325.
- [7] Gradient Boost Part 1 (of 4): Regression Main Ideas, You Tube, 2019, consulté en mars 2022.
- [8] Smart Building, Encyclopedia, consulté en mars 2022.
- [9] Maintenance prévisionnelle, Wipotec, consulté en mars 2022.
- [10] Random Forest Regression, consulté en mars 2022.
- [11] Understanding Random Forest, consulté en mars 2022.
- [12] Long Short-term Memory, Sepp Hochreiter, Jürgen Schmidhuber, 1997.
- [13] StackAbuse, consulté en mars 2022.
- [14] Intro to Recurrent Neural Networks LSTM, consulté en mars 2022.
- [15] Introduction à la prédiction de séries temporelles , programme Python créé par Vincent Imard.
- [16] Data Science and Energy: Some Lessons From Europe on Higher Education Course Design and Delivery, HDSR, janvier 2022.
Pour citer cet article :
Machine learning appliqué au domaine de l’énergie, Pierre-Thomas Demars, Vincent Imard, Benoit Delinchant, mai 2022. CultureSciences Physique - ISSN 2554-876X, https://culturesciencesphysique.ens-lyon.fr/ressource/IA-energie-Delinchant.xml